
Zeroscope AI Text to Video | Image to Video

Zeroscope AI is an advanced text-to-video generation tool that transforms written descriptions into high-quality video content. It is an open-source model developed as an improvement over Modelscope, featuring higher resolution outputs, no watermarks, and a closer aspect ratio to 16:9.
Price: Open Source
Operating System: Web Application
Application Category: AI Video Generator
4
What is Zeroscope AI?
Zeroscope AI is an advanced text-to-video generation tool that transforms written descriptions into high-quality video content. It is an open-source model developed as an improvement over Modelscope, featuring higher resolution outputs, no watermarks, and a closer aspect ratio to 16:9.
The tool comprises two main components:
- Zeroscope_v2 567w: This is designed for rapid content creation at a resolution of 576×320 pixels.
- Zeroscope_v2 XL: This component allows for upscaling to a higher resolution of 1024×576, enhancing the quality of the final product.
Zeroscope AI Overview
| AI Tool | Zeroscope AI |
| Category | Video Generator |
| Feature | Text to Video |
| Accessibility | Online at Hugging Face (Zeroscope Studio) |
| Supported Input | English text prompts |
How to use using Zeroscope AI?
To generate a video using Zeroscope AI, follow these steps:
Step 1. Access Zeroscope AI
Visit Hugging Face:
Go to the Zeroscope AI page on Hugging Face: https://huggingface.co/spaces/fffiloni/zeroscope
Step 2. Set Up Your Environment
Check System Requirements:
Ensure your system has a compatible graphics card and enough computational resources to run the model. Zeroscope can be resource-intensive, so a modern GPU is recommended.
Install Dependencies:
If running locally, you will need to install necessary libraries and dependencies. Typically, this involves installing PyTorch and other related packages.
pip install torch torchvision torchaudio
pip install transformers diffusersStep 3. Load the Model
- If running locally, get the Zeroscope model from Hugging Face.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "damo-vilab/zeroscope"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)Step 4. Prepare Your Text Input
Craft Your Text Description:
Write a clear and descriptive text. The quality of the description directly impacts the quality of the generated video.
Step 5. Generate
Run the Model:
Input your text description into the model to generate the visuals. If using the Hugging Face demo, simply input your text and run the model on the website.
text_input = "A serene beach scene with waves crashing and the sun setting"
inputs = tokenizer(text_input, return_tensors="pt")
outputs = model.generate(**inputs)
video = outputs[0]Upscale (Optional):
- For higher resolution, you can use the
Zeroscope_v2 XLcomponent to upscale the video quality.
from some_upscaling_library import upscale_video
high_res_video = upscale_video(video, target_resolution=(1024, 576))Step 6. Review and Edit
Preview:
Watch the generated video to ensure it meets your expectations.
- Realistic Videos
- Generative Art
- Easy to Use
- No Watermark
How to use Zeroscope on HuggingFace?
Step 1: Access Zeroscope on Hugging Face
Open your web browser and go to Zeroscope on Hugging Face: https://huggingface.co/spaces/hysts/zeroscope-v2
Step 2: Prepare Your Text Prompt
In the text input box provided, type a clear and descriptive text that you want to convert into a video. For example, you might write, “A serene beach scene with waves crashing and the sun setting.”
Step 3: Adjust Advanced Options
- Seed:
- Locate the seed option. If you want a different video each time, set the seed to
-1. If you want to reproduce the same, enter a specific seed value (e.g.,0).
- Locate the seed option. If you want a different video each time, set the seed to
- Number of Frames:
- Set the number of frames. Note that changing the number of frames will affect the content. A typical setting might be
16frames.
- Set the number of frames. Note that changing the number of frames will affect the content. A typical setting might be
- Number of Inference Steps:
- Set the number of inference steps, which controls the refinement level of the video generation process. Higher values generally lead to better quality but take longer to process.
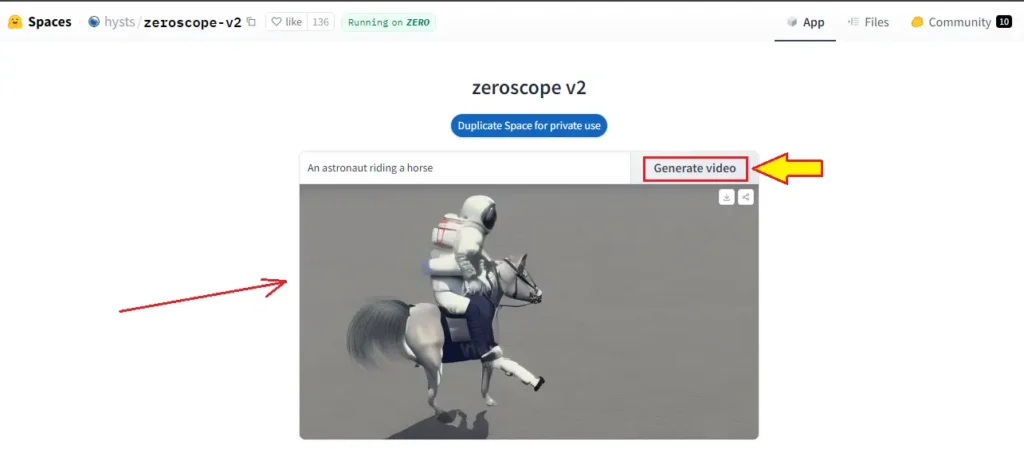
Step 4: Generate
After entering your prompt and adjusting the options, click on the “Generate” button. The system will process your prompt and generate the video based on the input text and settings.
Zeroscope AI Features:
Zeroscope AI is a powerful AI tool designed to convert text descriptions into video content. Here are the key features of Zeroscope:
1. High-Resolution Video Generation
Enhanced Resolution: Zeroscope offers video generation in higher resolutions, achieving up to 1024×576 pixels with its Zeroscope_v2 XL component.
2. Open-Source Accessibility
Open Source: Zeroscope is available as an open-source model, providing an accessible alternative to commercial text-to-video tools like Runway ML’s Gen-2.
Community Driven: Being open-source allows for community contributions and continuous improvements, enhancing its capabilities over time.
3. User-Friendly Interface
Ease of Use: The platform is designed to be user-friendly, allowing both beginners and experienced users to generate without needing advanced technical skills.
Intuitive Controls: Users can easily input text, select video styles.
4. Advanced AI and Machine Learning
Deep Learning Models: Zeroscope uses sophisticated algorithms and deep learning techniques to convert text into visually appealing content.
Parameter Rich: The model is built on a diffusion model with 1.7 billion parameters, ensuring detailed output.
5. Customization and Flexibility
Variety of Styles: Users can choose from various video styles and templates to match their specific needs and creative visions.
6. Efficient and Scalable
Rapid Content Creation: Designed for quick content generation, it allows users to create videos in minutes, significantly reducing the time and effort required compared to traditional methods.
7. No Watermarks
Professional Output: Zeroscope AI do not contain watermarks, ensuring professional-quality outputs suitable for various applications.
Zeroscope AI
Zeroscope AI Model Architecture
Here’s an overview of its key architectural components and mechanisms:
1. Multi-Level Diffusion Model
Zeroscope is built on a multi-level diffusion model architecture, which facilitates the conversion of text inputs into video outputs.
The model operates in several stages to ensure the generation of coherent and visually appealing video sequences.
2. Parameter Count
The model contains 1.7 billion parameters, which enable it to capture complex patterns and details necessary for generating high-quality content from textual descriptions.
3. Key Components
- Zeroscope_v2 567w:
- Resolution: Generates video at a resolution of 576×320 pixels.
- Purpose: Designed for rapid content creation, allowing users to explore video concepts quickly before committing to higher-resolution outputs.
- Zeroscope_v2 XL:
- Resolution: Upscales videos to a higher resolution of 1024×576 pixels.
- Purpose: Enhances the quality, initially created by the Zeroscope_v2 567w component, ensuring that final outputs are of professional quality.
4. Diffusion Process
The diffusion model at the core of Zeroscope operates by iteratively refining the content. Starting from a random noise input, the model applies a series of transformations guided by the textual description until a coherent video sequence is formed.
5. Deep Learning Techniques
Zeroscope leverages deep learning techniques, including convolutional neural networks (CNNs) and attention mechanisms, to interpret the textual input and generate corresponding video frames.
These techniques allow the model to understand and synthesize complex visual and temporal information effectively.
6. Training and Dataset
The model is trained on large datasets, which help it learn the mapping between textual descriptions and visual content.
This extensive training enables Zeroscope to generalize well across various types of text inputs, producing relevant and high-quality content outputs.
7. Scalability and Efficiency
Zeroscope’s architecture is designed to be both scalable and efficient, making it suitable for users who need to generate a large volume of video content.
FAQs:
1. What is Zeroscope AI?
Zeroscope is an AI tool that converts textual descriptions into high-resolution video content. It is built on a multi-level diffusion model with 1.7 billion parameters, allowing for the creation of create visual.
2. How does Zeroscope work?
Zeroscope uses a multi-stage diffusion process, starting with a low-resolution draft created by Zeroscope_v2 567w at 576×320 pixels. This draft can then be upscaled to 1024×576 pixels using Zeroscope_v2 XL for a higher-quality output.
3. What are the system requirements for running Zeroscope?
To run Zeroscope efficiently, it is recommended to have a modern graphics card (GPU) with sufficient computational resources.
4. Can I customize the videos generated by Zeroscope?
No, inside Zeroscope you can not customize or edit the videos.